Comment un algorithme de deep-learning pourrait prédire des saignements post-AVC
Publié par Axe Neurosciences - CHUGA, le 30 juin 2021 4.8k
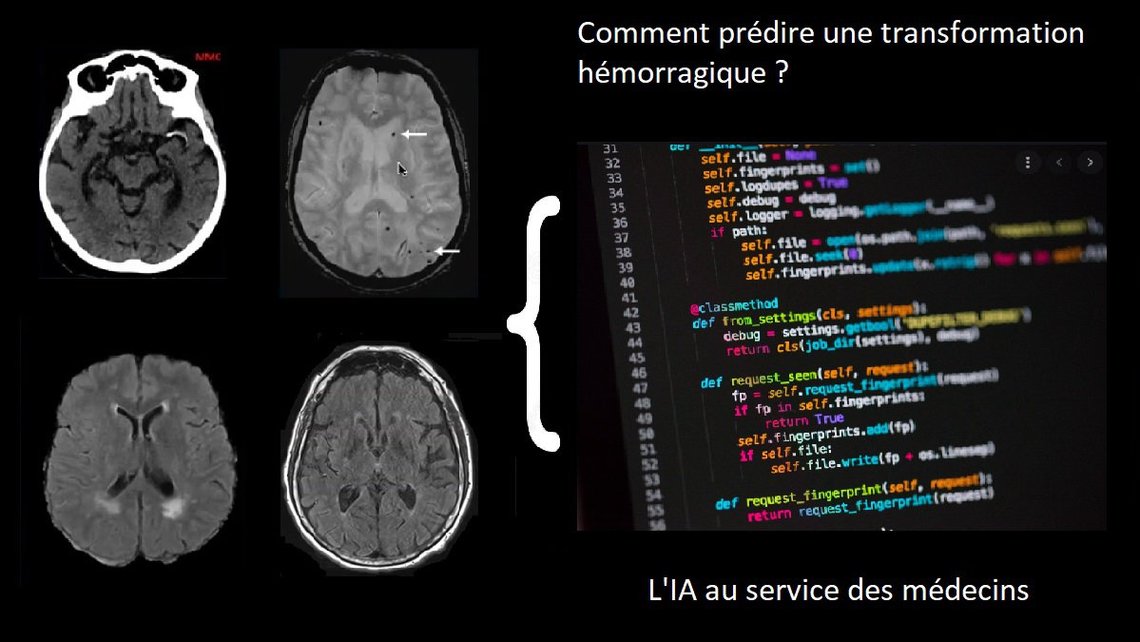
Est-il possible de prédire de façon précise les éventuels saignements au sein du cerveau après le traitement d'un AVC ? Responsables d'une augmentation des décès à court terme, mais aussi de handicaps et de troubles cognitifs à long terme, on ne sait - aujourd'hui - que très mal prédire leur survenue.
Voici une présentation des recherches de Loïc Legris, Stenzel Cackowski, Thomas Christen, Florent Lépilliet et Benjamin Lemasson, chercheurs au Grenoble Institut des Neurosciences (GIN). Voyons comment, avec un algorithme de deep-learning, il est envisagé d'améliorer drastiquement les méthodes de prédictions actuelles.
AVC ischémiques
Un AVC (accident vasculaire cérébral) se traduit par un déficit neurologique soudain, causé soit par un saignement (AVC hémorragique), soit par l’obstruction d’une artère entraînant un déficit d’oxygène et de glucose, carburants nécessaires au bon fonctionnement du cerveau (AVC ischémique). Ces derniers représentent environ 80% des AVC.
Afin de porter un diagnostic, une imagerie cérébrale est nécessaire. L’Imagerie par Résonance Magnétique (IRM) par exemple, permet de visualiser précisément les zones touchées. Si la prise en charge est suffisamment rapide, il est possible de proposer un traitement médicamenteux, la thrombolyse intra-veineuse, qui consiste à injecter une substance capable de dissoudre le caillot formé au sein de l’artère. Dans certains cas, une technique plus invasive est proposée (thrombectomie), qui consiste à aller chercher le caillot avec un cathéter depuis l’artère fémorale (au niveau de l’aine), jusqu’aux artères intra-cranienne.
Seulement, dans 20 à 40% des cas (et ce, même si l'opération précédente s'est bien déroulée), une transformation hémorragique (i.e. un saignement dans le cerveau) survient spontanément dans les jours suivant le traitement, bien souvent de manière asymptomatique. Cette transformation hémorragique peut avoir de lourdes conséquences, allant d'une augmentation du handicap déjà causé par l'AVC à l’apparition de troubles cognitifs et de démence à plus long terme, voire au décès. De plus, en retardant le traitement dit de “prévention secondaire” (anticoagulants, par exemple), elle diminue le contrôle sur le risque de récidive précoce d'AVC ischémique.
Aujourd'hui, plusieurs méthodes de prédiction pour la survenue d'une transformation hémorragique existent. Elles se présentent sous forme de scores, obtenus en pondérant différents facteurs connus pour augmenter les chances de saignements (âge, diabète, tension artérielle élevée, présence de micro-saignements sur l'IRM, etc). Seulement, leur précision laisse à désirer : dans le meilleur des cas, elles peinent à atteindre 75% de justesse dans leurs prédictions (parfois à peine plus de 50% - score que l'on obtiendrait en tirant à pile ou face) et ne sont donc pas utilisées en pratique courante.
Pour remédier à ce manque d'efficacité, il est désormais envisagé de se servir d’algorithmes d'intelligence artificielle (dits de "machine-learning" ou de "deep-learning") qui, ces dernières années, sont devenus très efficaces pour ce genre de tâches. Mais au fait, qu’est ce qu’un algorithme d'intelligence artificielle (IA) ?
Machine-learning
Faisons un petit détour par l'informatique pour bien comprendre l'utilité et les avantages des algorithmes de machine-learning et de deep-learning.
Dans un algorithme "classique", les données d'entrée sont traitées par une suite d'opérations, définies à l'avance par le programmeur. Par exemple, on peut dire à notre algorithme d'attribuer un score (basé sur une échelle prédéfinie) aux variables "âge", "tension artérielle", "temps entre l'AVC et le traitement", puis de faire la somme des 3 et de d'afficher le score final. Cette méthode est rapide et très facile, mais lorsque les données cliniques sont nombreuses (en général, une dizaine) et que l'on ne connaît pas l'importance de chacune dans le risque de saignement, il est impossible d'établir une formule précise qui pourra prédire avec précision s'il aura lieu ou non.
C'est à ça que servent les algorithmes de machine-learning. Comme leur nom l'indique, c'est le programme lui-même qui va apprendre l'importance des différentes données cliniques, autrement dit si l'une est plus influente que l'autre dans la survenue du saignement. Pour ce faire, on utilise ce que l'on appelle un réseau de neurones, censé simuler le fonctionnement des neurones humains. Un "neurone" informatique est une sorte de boîte dans laquelle vont arriver tous les scores de ces données cliniques. Son rôle est de faire leur somme, pondérée par des valeurs (ou poids) distribuées aléatoirement, et de transmettre le résultat que s'il est supérieur à un certain seuil déterminé par le programmeur. En faisant cela sur plusieurs neurones en même temps, on peut regarder en temps réel avec quelles combinaisons de poids l'algorithme conclut qu'il y aura un saignement, ou à un cas sans danger. Après avoir indiqué à l'algorithme avec quelles combinaisons il s'est trompé ou non (feedback), puis répétant l'opération un très grand nombre de fois sur un grand nombre de données (phase d'apprentissage), on obtient des poids de plus en plus précis, désormais ajustés par le programme lui-même au fil des "runs".
C'est sur ce principe que fonctionnent les meilleurs scores de prédiction actuels (dont la justesse ne dépasse pas 80% - ils ne sont pas utilisés en pratique), de même que certains algorithmes de reconnaissance d'images. Ils ont connu un "boom" dans leur utilisation il y a une dizaine d'années, et sont encore utilisés aujourd'hui. Seulement, ils ne fonctionnent que si l'on connaît les caractéristiques pertinentes à la résolution du problème (par exemple la tension du patient dans notre cas, ou la position des yeux sur un visage pour un algorithme de reconnaissance faciale). Et dans le cas des saignements post-AVC, c'est précisément la recherche des facteurs que l'on ne soupçonne/voit pas que l'on souhaite confier à l'algorithme. Ainsi, on utilise une méthode d'apprentissage "profond" à plusieurs couches de neurones, aussi appelée "deep-learning".
Deep-learning et IRM
C'est sur des données d'imagerie que nos cinq chercheurs souhaitent entraîner leur algorithme de deep-learning (projet : Artificial Intelligence in NeuroImaging - Hemorrhagic Transformations, AINI-HT). L'idée est de lui confier, en lui donnant les images d'IRM de patients déjà traités dont on connaît les éventuelles complications post-traitement, la tâche de définir quels sont les éléments présents sur l'image qui pourraient indiquer la survenue d’une future transformation hémorragique. Contrairement aux algorithmes précédents, qui connaissaient les données cliniques définies comme importantes, ces éléments ne sont que très mal connus, et les algorithmes de deep-learning devront les trouver eux-mêmes avant de définir les différents poids auxquels ils seront associés dans la recette finale. Les algorithmes actuels ont typiquement plusieurs centaines de couches et comportent plusieurs millions de neurones, mais ces chiffres varient beaucoup en fonction de la tâche qui leur est confiée. Ajouter des couches augmente considérablement les temps de calcul, mais permet de trouver des relations profondes - voire insoupçonnées - entre les différentes données.
Dans un premier temps, il faut traiter les images (pré-processing) pour uniformiser les données d’entrée du modèle, tout en conservant le maximum d'informations. Pour cela, on utilise un algorithme intermédiaire (réseau neuronal convolutif - CNN) qui va leur appliquer une succession de filtres, qui feront notamment ressortir les principales caractéristiques des images tout en réduisant leur nombre de pixels. On appelle cela la "réduction de la dimensionnalité", ou encore "l'abstraction de l'image".
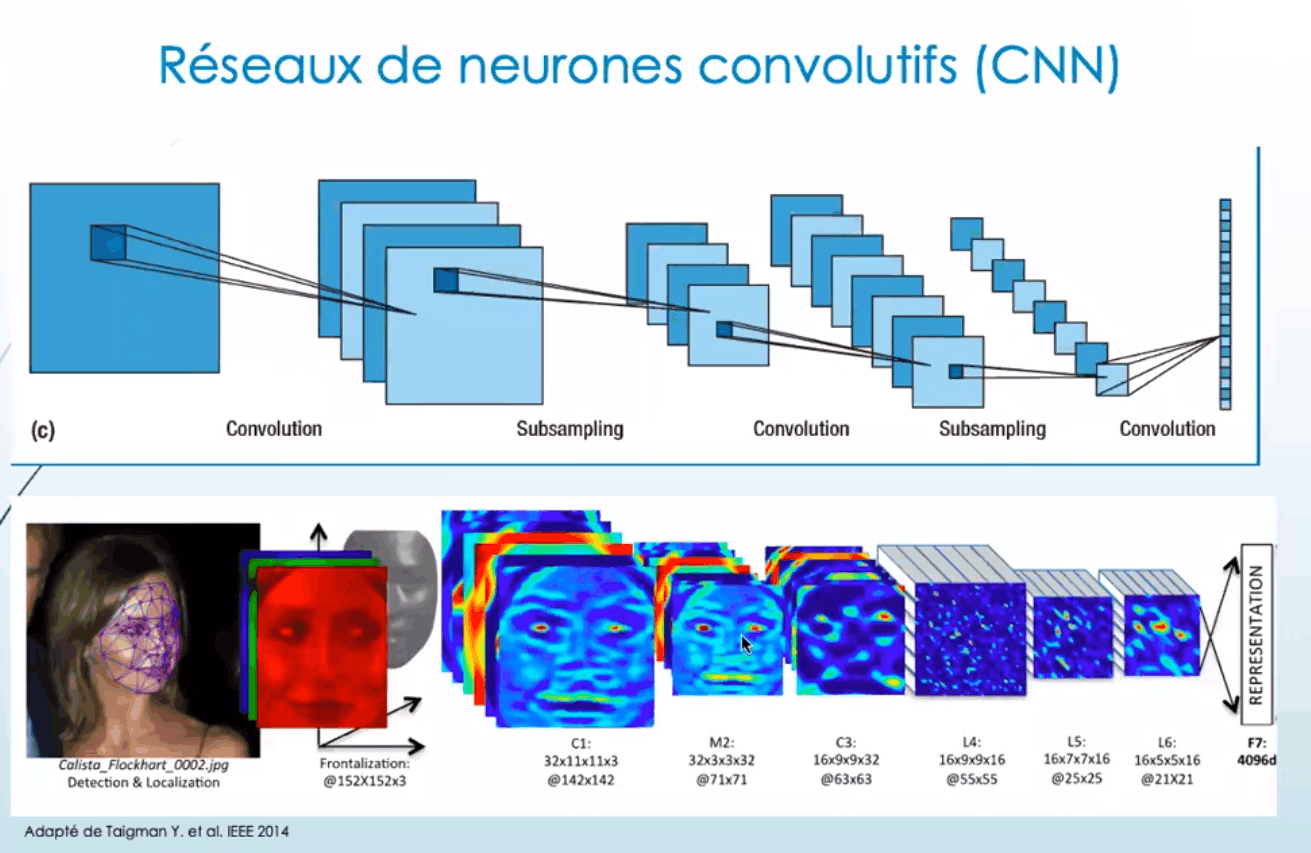
Une fois l'image dépecée et rendue lisible par l'algorithme, ses informations sont prêtes à être utilisées comme données d'entrées. Elles peuvent être couplées aux données cliniques "classiques" utilisées pour les scores de prédiction actuels, notamment pour déterminer si les images d'IRM seules suffisent, ou si elles doivent s'accompagner de données supplémentaires pour que l'algorithme établisse une prédiction assez précise. Il peut ainsi fonctionner "normalement", c'est-à-dire tester une multitude de combinaisons de poids dans l'élaboration de sa recette de prédiction. Faire tourner ce genre de programme est extrêmement long (au minimum plusieurs heures pour des runs simples) et nécessite des ordinateurs très puissants. La tâche des chercheurs est alors de bien paramétrer les données d'entrées, estimer quel doit être leur nombre idéal (sûrement plusieurs millions), déterminer les régions de l'image les plus pertinentes, de quelle manière appliquer les différents filtres, etc. Une fois le run terminé dans une certaine configuration, la recette de prédiction obtenue est testée sur des images IRM non-utilisées dans la phase d’apprentissage, pour ensuite ajuster les différents poids en fonction des réussites et des erreurs (feedback).
Les premiers résultats, obtenus par Stenzel Cackowski et Florent Lépilliet, donnaient un taux de précision proche de ce qui se fait actuellement de mieux en machine-learning. Les images d'IRM utilisées sont désormais plus nombreuses et de meilleure définition, ce qui devrait aider à améliorer les prédictions dans les mois à venir.
Les algorithmes de deep-learning sont au cœur de la plupart des intelligences artificielles actuelles. Les applications de ces programmes sont très nombreuses et dépassent désormais largement les capacités humaines sur un grand nombre de tâches. Google, Facebook, Amazon, Netflix ... Beaucoup d'entreprises les utilisent à foison, notamment pour améliorer leurs recommandations de contenus. Un algorithme de reconnaissance d'image est indissociable d'une voiture autonome, mais peut aussi faire la modération des contenus postés sur un réseau social, reconnaître de possibles mélanomes sur des photos de peau, ou dépister des rétinopathies diabétiques sur des images de rétines. Pour en savoir plus sur la place actuelle (et future !) de l'IA dans la médecine, rendez-vous ici.