Le LHC et le calcul distribué (2/2) : le défi des années 2010
Publié par ACONIT (Association pour un Conservatoire de l'Informatique et de la Télématique), le 7 juin 2023 2.3k

par Dr Fairouz Malek
En complément du premier volet sur le traitement des données et le calcul publié sur le site Echosciences-Grenoble le 23 mai dernier, nous pouvons légitimement nous poser la question de savoir ce que les systèmes et métiers dédiés au calcul, tels qu’évoqués dans l’article précédent, sont devenus. Une évocation de cette évolution des moyens dédiés aux travaux scientifiques de grande envergure nous est fournie par le témoignage d’une chercheuse grenobloise reconnue, d’origine franco-algérienne et membre de l’Académie Africaine des Sciences et membre associée de l’Académie Delphinale. Laissons-lui la parole.
Le LHC, acronyme anglais pour Large Hadron Collider, est le plus puissant accélérateur de particules subatomiques au mondei. Les particules sont accélérées à une vitesse proche de celle de la lumière et circulent dans un anneau de 27 km de circonférence enterré à 100 m sous terre, situé à cheval sur la frontière franco-suisse près de Genève. Mis en œuvre par le laboratoire européen du CERNii, le LHC et les équipements expérimentaux associés ont été conçus et construits par une collaboration internationale. A partir de 2009, il livre des données de collisions de protons de 7, 8 et 13 Téra électronvolts ou TeV (1 Téra=1012) dans le centre de masse de la collision. Quatre gigantesques expériences, mobilisant plus 10 000 scientifiques, ont permis d’observer des collisions entre les particules accélérées pour tenter de percer quelques-uns des mystères fondamentaux de l’origine de l’Univers, et, notamment, de découvrir le boson de Higgs en 2012iii.
Chaque collision proton-proton dans le LHC est « similaire » à un « mini Big-Bang ». Près d’une centaine de milliards de particules sont accélérées quasiment à la vitesse de la lumièreiv et entrent en collision toutes les secondes. En théorie, un seul boson de Higgs est produit tous les 10 milliards de collisions. Chaque collision génère des milliers de particules secondaires qui traversent les détecteurs des expériences. Si le détecteur était parfait (avec une « acceptance » de 100 %, une efficacité de détection des particules de 100 % et sans fausses identifications), les scientifiques auraient pu observer environ 500 000 bosons de Higgs pendant les deux premières années de prise de données. Or, il n’en a été détecté qu’une centaine. L’ampleur de la tâche s’apparente donc à rechercher une aiguille dans une énorme botte de foin !v
Traiter les données accumulées au LHC représente un véritable défi informatique, autant pour les flux, de l’ordre du Gigaoctet par seconde (109 octetsvi/sec) que pour leur volume, environ 30 Pétaoctets (1015 octets , Po) chaque année. A tout instant, quelques milliers de chercheurs du monde entier sollicitent des ressources de calcul et de stockage pour analyser ces données. Pour faire face à ce défi, la solution du calcul distribué, ou grille de calcul, s’est imposée. Elle a été mise en œuvre par la collaboration WLCGvii.
WLCG, pour Worldwide LHC Computing and Grid, est la traduction à l'échelle mondiale de l'esprit de mutualisation et d'optimisation des moyens de traitement des données qui prévaut dans la communauté de la physique des hautes énergies depuis le début des années 1960, période où naissent des centres de calcul nationaux dédiés comme le CC-IN2P3viii. Aussi, il est peu à peu devenu évident, à partir de 2002/2003, qu'il n’était plus possible de continuer à intégrer sans cesse plus de transistors dans des processeurs uniques, imposant de changer de concept en distribuant la puissance informatique sur de multiples unités de traitement moins puissantes. La loi de Moore a en effet atteint ses limites et n’est ici plus valide. Le principal intérêt de ce système fondé sur la mise en commun des ressources réside dans ses capacités quasi infinies et dans son évolution en continu, à la différence des machines massivement parallèle. Il suffit en effet d’ajouter de nouvelles entités pour augmenter d’autant les capacités de calcul de la grille. Celles-ci peuvent égaler les supercalculateurs en puissance de calcul, bien qu'elles soient limitées par les capacités de transfert entre processeurs, mais leur principal atout est de traiter des quantités énormes de données réparties sur la grille.
Si nous évaluons les capacités des supercalculateurs en Tflops/sec (floating-point operations per second), ce sont, pour les grilles informatiques, les Pétaoctets de données stockées, échangées et distribuées qui sont la bonne mesure. Les grilles sont centrées sur l'analyse d'énormes quantités de données en s'appuyant sur de très nombreux ordinateurs, mondialement distribués. Ceci permet, dans une certaine mesure, de partager le coût mondialement et proportionnellement aux ressources mises à disposition par chacun des pays contributeurs. La grille WLCG compte près de 170 sites répartis sur 4 continents, dont une dizaine en Franceix.
Lorsqu’une requête est formulée par un utilisateur à partir de l’un des nombreux points d’entrée du système, la grille de calcul établit l’identité de l’utilisateur, vérifie ses autorisations, recherche les sites disponibles et susceptibles de fournir les ressources requises, en termes de stockage, de capacité de calcul, de disponibilité des logiciels d’analyse… pour finalement satisfaire la requête de l’utilisateur sans que ce dernier ait à se soucier du détail du processus. Elle est hiérarchisée en quatre niveaux, ou rangs, appelés « Tier » (Figure 1). L’appartenance à un rang donné fixe la nature et la qualité des services qu’un centre de calcul doit fournir.
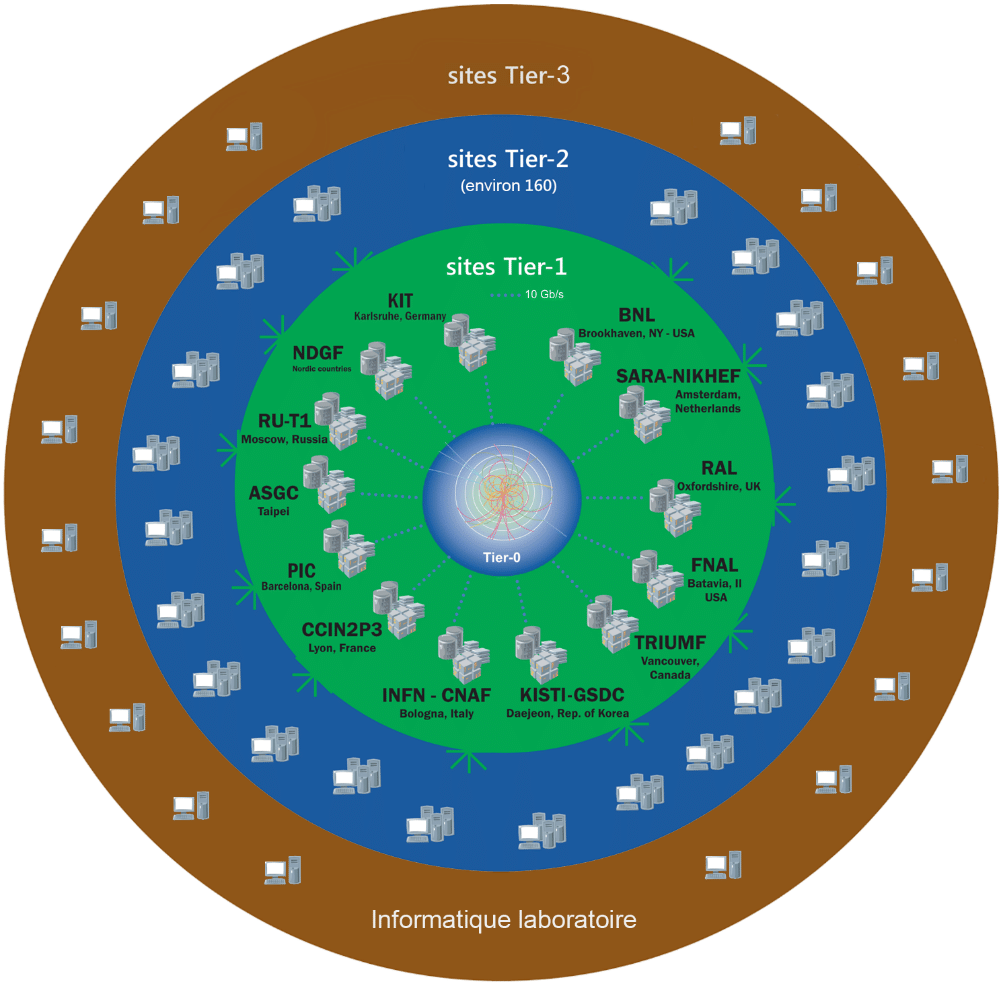
Figure 1: L’infrastructure WLCG selon les rangs appelés « Tier ». Le Tier-0 (CERN) collecte les données brutes des expériences et les distribue aux Tier-1 qui les stockent et les traitent pour en tirer des données « physiques ». Ces derniers les distribuent aux Tier-2 pour un traitement exploitable par les physiciens. Le Tier-3 sert à l’analyse in fine et est localisé dans un laboratoire, un institut ou tout simplement un PC.
Le réseau privé optique du LHC (LHCOPN) et l'environnement de réseau ouvert du LHC (LHCONE)x ont été conçus pour répondre aux exigences de mise en réseau des nouveaux modèles de calcul. LHCOPN, réservé aux transferts et à l'analyse des données du LHC et connectant le Tier-0 (CERN) et les Tier-1, permet une bande passante de 10 Gbps (Gbit/s) jusqu’à 2015, puis 20 et 40 Gbps à partir de 2018, pour répondre aux exigences du nouveau modèle informatique qui nécessite le transfert de données entre n'importe quelle paire de sites Tier-1, Tier-2 et Tier-3. Les connexions transatlantiques se sont régulièrement améliorées, mettant en place trois liaisons de 100 Gbps s'étendant jusqu'au CERN à travers l'Europe.
Aujourd'hui, WLCG a accès à quelque 600 000 cœurs (CPU)xi et 500 Po de stockage, fournis par les 170 sites collaborateurs dans 42 pays, ce qui a permis à la Grille d'établir un nouveau record en octobre 2015 en exécutant un total de 51,1 millions de tâches (jobs).
A partir de 2022, la capacité d’acquisition des données du LHC est encore supérieure d’un facteur 100. Pour accompagner cette augmentation de la consommation en énergie et de la luminosité (taux d’événements susceptibles d’être traités), les technologies de calcul et de stockage sont améliorées. Ainsi, le calcul parallèle permet de gagner en vitesse de calcul pour traiter plus d’événements et le GPU (Graphics Processing Unit) améliore la vitesse des algorithmes, en particulier ceux qui permettent la recherche des traces de particules chargées au plus près de la collision. Le stockage, cependant, reste encore un problème. Le Cloud n’est pas une solution optimale, car l’accès aux données de manière intensive ne s’y prête pas bien, et le stockage dans un site type Tier-2 implique une gestion quotidienne trop lourde. La solution intermédiaire a été de constituer des sites sans stockage, qui iraient lire les données à distance.
Après un modèle de calcul très centralisé dans les années 1980-1990, un modèle de grille hyper distribué dans les années 2010, la tendance est actuellement au retour vers un modèle reposant sur un petit nombre de centres de calcul très robustes et très bien connectés. Par ailleurs, le développement de la « science ouverte », dans la continuité de l’Open Source en informatique, devrait aboutir dans les prochaines années à une ouverture complète des données, des algorithmes et logiciels de traitement, permettant de garantir la reproductibilité des résultats scientifiques.
Et à Grenoble ?
1989 a vu l'arrêt progressif des moyens de traitement du Service de Calcul commun à l'ISNxii et aux laboratoires CNRS du Polygone scientifique, parallèlement à la mise en place de moyens propres à l'ISN et au CNRS (délégation Alpes). Le Service de Calcul de l’ISN a été réinstallé dans le bâtiment principal du laboratoire. Un cluster de stations de travail DIGITAL a été mis en place sur le réseau ETHERNET pour traiter des applications spécifiques (CAO mécanique et électronique, dépouillement de données) ou plus générales (calcul scientifique, gestion, acquisition de données). Un ordinateur départemental IBM 9375-60 a été installé début 1988, pour effectuer principalement du dépouillement de données. Cette machine a été incrémentée début 1989 d'un contrôleur de disques, de deux unités de disques de 855 Mo et de huit voies asynchrones. Elle est reliée à l'autocommutateur par 14 voies asynchrones au réseau ETHERNET et à l'IBM 3090-600 du CC-IN2P3 (Lyon). Après câblage d'une bonne partie des bureaux, 40 consoles alphanumériques et/ou graphiques (C-ITOH 224, FALCO 5220) ont été distribuées.
Au cours des années 2002/2003, l’évolution du parc informatique du LPSC (nouveau nom de l’ISN) s’est caractérisée par l’augmentation du nombre de PC sous Linux (135 postes fin 2003), et du nombre de PC fixes sous Windows (près de 200 fin 2003) et la quasi-disparition des Macintosh et des terminaux X. Un autre phénomène important pendant cette période est le déploiement du parc des portables, passé de quelques unités à plus de soixante, fin 2003, signalant le début de ce qu’on nommera le “nomadisme informatique”. La capacité disque disponible sur les 4 serveurs NFSxiii du laboratoire était de 7 To (1012 octets) et la totalité des services a été transférée sur système Linux.
En 2007, 60 To de données sont répartis sur 8 serveurs et les sauvegardes sont désormais effectuées au Centre de Calcul de Lyon (CC-IN2P3). Cela permet une mutualisation des moyens et une meilleure sécurité des données grâce à la délocalisation de la sauvegarde. Cette période a vu une augmentation significative du parc de serveurs de calcul et la mise en place d’un Tier-3 pour les expériences du LHC, Alicexiv et ATLASxv, portant à 244 le nombre de cœurs disponibles. Un secours du point d’accès au réseau Renater (Réseau National de télécommunications pour la Technologie de l’Enseignement et la Recherche)xvi via l’ESRF (le synchrotron européen basé à Grenoble)xvii a été mis en œuvre sur une liaison fibre optique multimode permettant un débit de 100 Mbits/s (106 bits/s) . Le point d’accès principal au réseau Renater a évolué vers une liaison fibre optique monomode permettant une augmentation de débit de 100 Mbits/s à 1 Gbits/s. Avec la mise en fonctionnement du LHC, les besoins de grille de calcul sont devenus importants, ce qui a motivé le passage du site Tier-3 au niveau Tier-2 en 2011 (voir Figure 2). Le nombre de cœurs de calcul disponibles est passé de 250 à 700, tandis que l’espace de stockage a progressé de 130 To à 700 To. En 2013, un deuxième système de virtualisation basé sur VMWARExviii a été mis en place pour regrouper les services de la grille sur une plateforme matérielle de 3 serveurs. Les capacités de calcul et de stockage du Tier-2 ont régulièrement augmenté pour atteindre, en 2018, 1668 cœurs et un stockage net de 1,3 Po.
Entre 2011 et 2013, la collaboration du LPSC avec CIMENT (un cluster/grille de calcul haute performance basé sur le campus universitaire de Saint-Martin d’Hères)xix s’est renforcée. Dans ce cadre, le LPSC a pu utiliser en production et de façon massive la grille de CIMENT, avec, en pic, plus de 700 jobs indépendants mono-cœur en simultané sur cette grille (autant que la capacité de la grille du site du LPSC).

Figure 2 : Le Tier-2 du LPSC Grenoble.
Epilogue
Tout cet environnement dédié, très technologique, nécessite, de fait, une maintenance permettant une opérabilité en continu des systèmes. La rédactrice de cet article, Fairouz Malek, est une physicienne de renommée internationale ayant contribué à la découverte du boson de Higgs et qui a occupé le poste de responsable scientifique de l’infrastructure nationale LCG-Francexx de 2004 à 2014, s’investissant dans l’amélioration des technologies de calcul au service des expériences de physique nucléaire et de physique des particules du LHC auxquelles elle participe. Elle est aussi l’autrice de plusieurs articles de magazines scientifiques sur ce sujet dont :
- F. Malek, chapitre “Le CERN et les Big Data », dans Les Big Data à découvert, CNRS Editions (2017), ISBN-978-2-271-11464-8.
- F. Malek, Les pétaoctets du LHC. Pour la Science, Pour La Science 433 (2013), 36-37 .
- F. Malek, Le calcul scientifique des expériences LHC. Reflets de la Physique 20 (2010) 11-15; DOI : 10.1051/refdp/2010016 .
- F. Malek, Grille informatique, l'union fait la force de calcul. Micro Hebdo no 655 (2010) 36.
Notes :
i LHC : https://home.cern/fr/science/accelerators/large-hadron-collider
ii CERN : https://home.cern/fr
iii Découverte du boson de Higgs : https://home.cern/fr/science/physics/higgs-boson
iv Vitesse de la lumière = 299 792 458 m /s.
v BD de Lison Bernet : https://www.lhc-france.fr/spip.php?article580, Mai 2011.
vi Un octet est un multiplet de 8 bits. Le bit est l'unité la plus simple dans un système de numération, ne pouvant prendre que deux valeurs, désignées le plus souvent par les chiffres 0 et 1.
vii WLCG : https://wlcg-public.web.cern.ch/
viii CC-IN2P3 : https://cc.in2p3.fr/
ix LCG-France : http://lcg.in2p3.fr/
x LHCOPN and LHCONE : Status and Future Evolution, E. Martelli and S. Stancu, J. Phys. : Conf. Ser. 664 (2015) 052025
xi CPU : Un processeur (ou unité centrale de calcul, en anglais central processing unit, CPU) est un composant présent dans de nombreux dispositifs électroniques, qui exécute les instructions machine des programmes informatiques.
xii ISN/LPSC : https://lpsc.in2p3.fr/
xiii Network File System (NFS), ou système de fichiers en réseau, est une application client/serveur qui permet à un utilisateur de consulter et, éventuellement, de stocker et de mettre à jour des fichiers sur un ordinateur distant, comme s'ils étaient sur son propre ordinateur.
xiv Alice : https://home.cern/fr/science/experiments/alice
xv Atlas : https://atlas.cern/
xvi Renater : https://www.renater.fr/
xvii ESRF : https://www.esrf.fr/
xviii VMware est une société de logiciels spécialisée dans la virtualisation et le cloud computing. La virtualisation consiste à créer une représentation logicielle de quelque chose, un serveur par exemple, afin de pouvoir y accéder et l’utiliser sans se soucier des contraintes liées à son matériel physique.
xix GRICAD/CIMENT : https://gricad-doc.univ-grenoble-alpes.fr/hpc/
xx Fairouz Malek : responsable scientifique de LCG-France
(texte mis en forme par Xavier Hiron)


