Patrimonialisation scientifique et technique : Les cartes graphiques Nvidia, du jeu vidéo aux calculs scientifiques (8/10 – année 2020)
Publié par ACONIT (Association pour un Conservatoire de l'Informatique et de la Télématique), le 12 octobre 2020 2.5k

Photo d'en-tête : Différents modèles de rendu du traitement des ombres par cartes graphiques (par mapping et rayonnement ligne à ligne).
Par Xavier Hiron, gestionnaire de collections (ACONIT),
à partir de notes compilées par Jean Ricodeau (ACONIT)
Contrairement à ce que l’on pourrait penser spontanément, les produits les plus développés ne proviennent pas tous de la recherche, pour irriguer ensuite le marché commercial. Un exemple du phénomène inverse est illustré avec un composant graphique additionné d'un produit logiciel, mis conjointement au point pour des besoins spécifiques en jeux vidéos. Leurs qualités ont ensuite intéressé les chercheurs qui les ont réemployés dans de nouvelles filières. Étudions ce phénomène surprenant de plus près.
Un besoin initial identifié en traitement graphique
A partir des années 1985, les outils informatiques de traitements graphiques ont eu beaucoup de succès dans les jeux vidéos. Ils permirent d'introduire les interactions entre plusieurs joueurs sur des images hautement dynamiques. A partir de 1995, la société californienne Nvidia acquiert rapidement une position dominante dans ce domaine, initialement en lien avec la société STMicroelectronics et son laboratoire de recherche de Grenoble.
Durant cette période, avec la miniaturisation à outrance des composants électroniques, l’augmentation du nombre de transistors intégrables sur une seule puce avait permis d’obtenir des processeurs multiples (appelés Multi-cores). Ces cœurs spécialisés individuellement effectuaient des traitements numériques particuliers, tandis que la logique séquentielle des programmes informatiques devait être segmentée en éléments de traitement (« threads ») à attribuer à tel ou tel cœur (1).
A partir des années 2002, la société Nvidia a développé des processeurs graphiques multicores et multithreads, massivement parallèles, avec des matériels (« hardwares ») et des logiciels (« softwares ») spécialisés, pour des traitements graphiques réclamant des calculs de types vectoriels (géométrie tridimentionnelle) et matriciels (algèbre linéaire). Le marché des nouvelles machines graphiques à architecture matérielle spécialisée était en plein essor, requérant des logiciels adaptés aux spécificités de ces équipements. Les jeux à joueurs multiples en visualisation 3D créèrent en effet une demande sur le marché qui induisait des besoins exceptionnels en performances techniques et en rapidité d'exécution des processeurs graphiques. Le contexte était donc favorable à cette évolution technologique.
Une explosion de la miniaturisation des composants
En marge de cette évolution de cumul des processeurs sur une seule et même puce, il était devenu possible d'associer à chacun de ces processeurs une mémoire dédiée (on parle de « cache » mémoire) dans sa proximité immédiate. Cette configuration permet d’augmenter considérablement la fréquence des cycles de lecture-écriture des données situées dans cette micro-mémoire. Le délai de lecture-écriture en mémoire étant raccourci, il devenait intéressant d’augmenter encore le nombre des processeurs, donnant ainsi la possibilité de mener plusieurs tâches de traitements en parallèle, et donc de gagner à nouveau en vitesse d'exécution. Ces cœurs dans le processeur pouvaient ainsi être spécialisés et optimisés pour tel ou tel type de traitement.
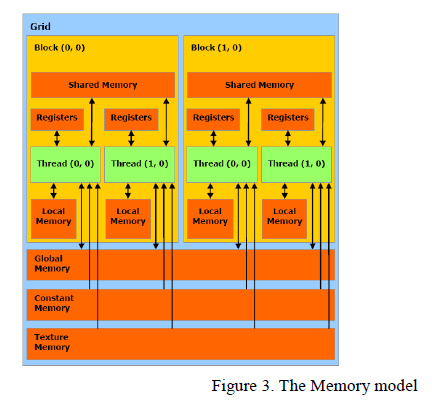
Schéma 1 : le modèle mémoire dans l'architecture d'une carte graphique
Il en résulta une révolution bouleversant les traitements séquentiels sur les ordinateurs, tels qu’usuellement associés au principe de la machine universelle de Turing depuis plus d'un demi-siècle. De nouvelles possibilités s’ouvraient en rapidité de calculs sur les images graphiques, avec des outils de traitements parallèles inscrits dans l’architecture même des puces. En 2006 fut créé le logiciel CUDA (Compute Unified Device Artitecture), un nouveau type de programme capable d’attribuer tel segment, ou thread, à telle spécialité de coeur sur une puce. Une hiérarchie est ensuite attribuée aux différents blocs de threads, couplée à un index les identifiant selon qu’ils correspondent à des traitements sur une, deux ou trois dimensions vectorielles. Ainsi naîtra notamment la carte graphique Nvidia GeForce GTX 660, qui s'adressait aux joueurs les plus aguerris. Pour donner un ordre de grandeur, cette carte, datée de 2012, utilise un processeur formé de 3 540 millions de transistors (3,54 fois 10**9 transistors en gravure de 28 nanomètres (nm)), sur une puce de seulement 300 mm² de surface !
Le passage au domaine scientifique
Ces nouvelles machines graphiques se sont avérées très performantes pour les applications des jeux vidéos, et ont pu être par la suite adoptées pour des activités de calculs scientifiques. Ces configurations ont permis de décupler les puissances de calculs des nouveaux ordinateurs, mais en introduisant cependant un inconvénient : le logiciel, et plus particulièrement les programmes écrits par l’utilisateur final, est devenu dépendant de la structure matérielle (« hardware ») des multiprocesseurs, et l’utilisateur/programmeur doit acquérir de nouvelles compétences pour pouvoir prendre en compte cette structure.
Mais pour des scientifiques de formation, cet aspect ne présentait pas de difficulté majeure. Ils ont pu créer de nouveaux outils logiciels adaptables aux calculs scientifiques complexes de traitements matriciels et utilisant des volumes restreints. A Grenoble, le CEA et l’ILL ont utilisé assez tôt des machines avec ces nouveaux types d’outils pour des applications gourmandes en calculs : reconstruction d’images en tomographie médicale (CT-scanners), en neutronique et cristallographie (rotation d'objet), en imagerie radar (illusion de continuité entre deux images, simulation d'un éloignement). La collection de l’ACONIT conserve au moins un exemplaire de carte graphique GTX 660 (AC_26089-02) provenant de ces laboratoires (2).
Une caractéristique de ces cartes additionnelles haute performance est le recours à un système de refroidissement augmenté. Les deux ventilateurs traditionnels ne suffisant plus, il leur a été adjoint un ensemble inédit de « caloducs », sorte de tuyaux canalisant la chaleur directement depuis le processeur graphique jusqu'aux radiateurs.
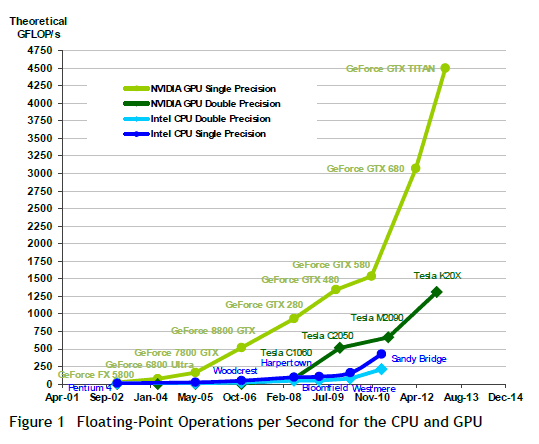
Courbe 2 : augmentation du nombre d'opérations par seconde : en bas, les produits d’Intel de type CPU (Compute Processing Unit) tels que le Pentium (2002), le Blomfield Westmare et le Sandy Bridge (2011). A l’opposé, Nvidia identifie désormais ses produits comme GPU (Graphic Processing Unit).
Conclusion : une histoire de concurrence
Vers l'année 2013, le marché du composant électronique a pensé que la société Nvidia était proche de sa disparition, parce que le géant Intel commençait à vendre des processeurs avec carte graphique intégrée pour PC, comme le “Intel Sandy Bridge”. Nvidia a alors vendu ses brevets à Intel pour en obtenir de l'argent frais. Puis Nvidia a investi dans des processeurs pour téléphone, mais sans grand succès. Plus récemment, le marché des jeux vidéos a redécollé et permis à Nvidia de revenir au premier plan, parce que les performances d'Intel étaient moindres, notamment pour ce qui concerne la polyvalence de ses processeurs. Nvidia s'en est donc finalement sorti par le haut, c'est-à-dire grâce à l'innovation.
Pour aller plus loin :
(1) voir l'article L’architecture des ordinateurs parallèles (4/10 - année 2019), Philippe Denoyelle et Jean Ricodeau (ACONIT) suivre le lien
(2) voir la fiche AC_26089-02 de DBAconit (carte graphique GTX660, NVIDIA) : suivre le lien
Le nanomètre, de symbole nm, est une unité de longueur du Système international d'unités (SI). Sous-multiple du mètre, il équivaut à un milliardième de celui-ci (ou 10-9).
Remerciement à Philippe Denoyelle pour sa relecture attentive.


